")
")
")
")
")
Az egyszerű mintaillesztés műveletigénye legjobb esetben n-es volt; most ezen próbálunk javítani. Az algoritmus, amelyet ismertetünk A Boyer-Moore mintaillesztés több javasolt változata körül az, amelyiknek a Quick Search (QS) nevet adta a szerzője (Horspool).
Az előző fejezetben ismertetett KMP eljárás a mintán belüli karaktersorozat előzetes elemzése révén jutott hatékony mintaillesztéshez. A QS algoritmus más stratégiát követ. Ha az illeszkedés elromlik, akkor a szövegnek a minta utáni első karakterét (S[k+m+1]) vizsgálja. Ennek a karakternek a függvényében dönti el, hogy hány pozícióval lépteti jobbra a mintát.
Az eljárás működése során az alábbi két esetet különböztetjük meg:
1.A szöveg minta utáni első karaktere nem fordul elő a mintában, azaz 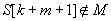 . Ekkor bármely olyan illesztés sikertelen lenne, ahol az
. Ekkor bármely olyan illesztés sikertelen lenne, ahol az 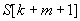 pozíció fedésben lenne a mintával. Tehát ezt a pozíciót "átugorhatjuk" a mintával, és a szöveg következő,
pozíció fedésben lenne a mintával. Tehát ezt a pozíciót "átugorhatjuk" a mintával, és a szöveg következő, 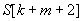 indexű karakterétől kezdhetjük újra, a minta elejétől kezdve, az illeszkedés vizsgálatát. Ezt az esetet illusztrálja a 33.1. ábra.
indexű karakterétől kezdhetjük újra, a minta elejétől kezdve, az illeszkedés vizsgálatát. Ezt az esetet illusztrálja a 33.1. ábra.
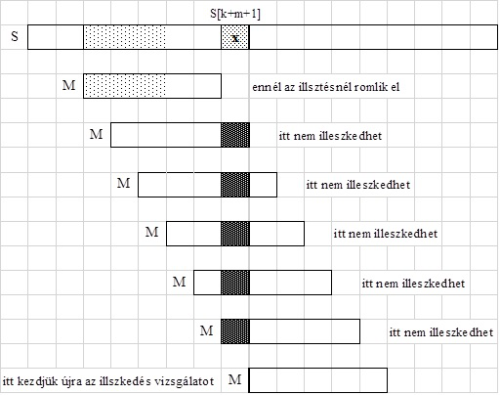 fej33_498_full.png33.1. ábra. Példa: a szöveg minta utáni első karaktere nem fordul elő a mintában
fej33_498_full.png33.1. ábra. Példa: a szöveg minta utáni első karaktere nem fordul elő a mintában2.A szöveg minta utáni első karaktere előfordul a mintában, azaz 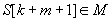 . Ekkor vegyük a mintabeli előfordulások közül jobbról az elsőt (balról, a minta elejétől számítva az utolsót) és annyi pozícióval léptessük jobbra a mintát, hogy ez a mintabeli karakter fedésbe kerüljön a szöveg
. Ekkor vegyük a mintabeli előfordulások közül jobbról az elsőt (balról, a minta elejétől számítva az utolsót) és annyi pozícióval léptessük jobbra a mintát, hogy ez a mintabeli karakter fedésbe kerüljön a szöveg 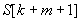 karakterével, majd a minta elejétől kezdve vizsgáljuk meg újra az illeszkedést. Ez az eset látható a 33.2. ábrán.
karakterével, majd a minta elejétől kezdve vizsgáljuk meg újra az illeszkedést. Ez az eset látható a 33.2. ábrán.
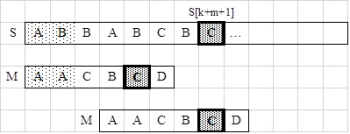 fej33_501_full.png33.2. ábra. Példa - szöveg minta utáni első karaktere előfordul a mintában
fej33_501_full.png33.2. ábra. Példa - szöveg minta utáni első karaktere előfordul a mintábanAz 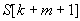 karakternek azért kell jobbról az első mintabeli előfordulását tekinteni, mert ha létezik egy ettől balra lévő előfordulás is, és amennyiben azt választanánk, akkor esetleg átlépnénk egy jó illeszkedést, mint ahogyan a 33.3. ábrán látható esetben ez megtörténik. Akárcsak a KMP algoritmusnál, itt is követni kell az óvatos legkisebb biztonságos eltolás elvét.
karakternek azért kell jobbról az első mintabeli előfordulását tekinteni, mert ha létezik egy ettől balra lévő előfordulás is, és amennyiben azt választanánk, akkor esetleg átlépnénk egy jó illeszkedést, mint ahogyan a 33.3. ábrán látható esetben ez megtörténik. Akárcsak a KMP algoritmusnál, itt is követni kell az óvatos legkisebb biztonságos eltolás elvét.
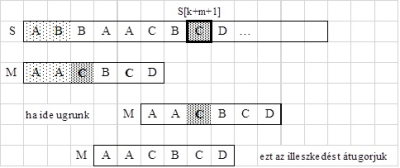 fej33_503_full.png33.3. ábra. Példa egy jó illeszkedés átugrására
fej33_503_full.png33.3. ábra. Példa egy jó illeszkedés átugrásáraA QS algoritmusnak is a lényegi részét adja a minta alkalmas eltolásának ismételt végrehajtása. Az eltolás mértékének meghatározása bevezetjük a shift függvényt, amely az ábécé minden betűjére megadja az eltolás nagyságát, ha az illeszkedés elromlása esetén az illető betű lenne a szöveg minta utáni első karaktere.
Definíció: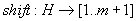
Megjegyzések:
Most nézzük a shift függvény értékeinek a kiszámítására szolgáló initshift eljárást, amelynek algoritmusát a 33.4. ábra szemlélteti..
Az első ciklus feltölti a shift tömböt az m+1 értékkel. A második ciklus adja meg a minta össze betűjére – a jobbról az első mintabeli elfordulásának megfelelő – ugrás nagyságát. Azért balról-jobbra megyünk végig a mintán, hogy a többször előforduló betűk esetén az utolsó (jobbról az első) előfordulásnak megfelelő léptetést jegyezzük fel.
 fej33_506_full.png33.4. ábra. Az inshift eljárás algoritmusa
fej33_506_full.png33.4. ábra. Az inshift eljárás algoritmusaA QS algoritmus a shift függvény értékeinek kiszámításával kezdődik, majd k eltolásokkal próbáljuk illeszteni a mintát. Amennyiben az illeszkedés elromlik, akkor a shift függvénynek megfelelően változtatjuk az eltolás mértékét. (Ügyelnünk kell arra is, hogy amikor a mintát a szöveg végére illesztjük, és az illeszkedés elromlik, akkor ne olvassunk túl a szövegen.)
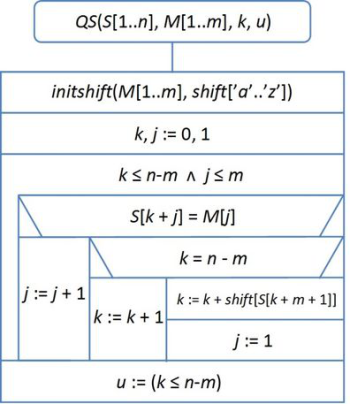 fej33_508_full.png33.5. ábra. A QS mintaillesztés algoritmusa
fej33_508_full.png33.5. ábra. A QS mintaillesztés algoritmusaA műveletigény meghatározását a legjobb esettel kezdjük. Ha a minta olyan karakterekből áll, amelyek nem fordulnak elő a szövegben, akkor már a minta első karakterénél elromlik az illeszkedés. Továbbá, ha a szövegben a minta utáni karakter nem fordul elő a mintában, akkor azt átugorhatjuk. Ezt az esetet illusztrálja a 33.6. ábra.
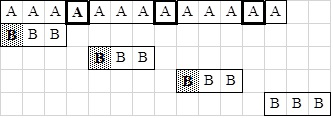 33.6. ábra. A QS algoritmus számára legkedvezőbb eset
33.6. ábra. A QS algoritmus számára legkedvezőbb esetA legkedvezőbb esetben a műveletigény:
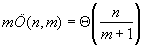
A legrosszabb esetben egyrészt a minta végén romlik el az illeszkedés, másrészt mindig csak kicsiket tudunk ugrani. Ilyen esetet mutat a 33.7. ábra.
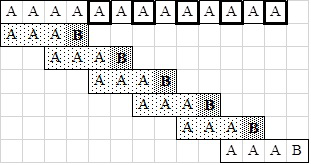 33.7. ábra. A QS algoritmus számra legkedvezőtlenebb eset
33.7. ábra. A QS algoritmus számra legkedvezőtlenebb esetA legkedvezőtlenebb esetben a műveletigény:
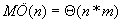
A QS algoritmust szekvenciális input fájlra, illetve más, közvetlenül nem indexelhető sorozatra, csak puffer használatával lehet alkalmazni, mivel – ahogyan az a legrosszabb esetben is látható – szükség lehet a szövegben való visszalépésre.
 |
 |
A tananyag az ELTE - PPKE informatika tananyagfejlesztési projekt (TÁMOP-4.1.2.A/1-11/1-2011-0052) keretében valósult meg.
A tananyag elkészítéséhez az ELTESCORM keretrendszert használtuk.