")
")
")
")
")
Az útvonaltervezés az egyik leggyakrabban végrehajtott eljárása a gráfok alkalmazásai körében. A feladat például a közlekedésben jelentkezik. A gráfot itt az a térkép jelenti, amely tartalmazza a kiindulási pontot és a célállomást, amellett a szóba jövő utak sem futnak le róla.
Az egyes útszakaszok megtételéhez (például üzemanyag és idő) ráfordítás szükséges, ezért olyan utat szeretnénk ezekből a szakaszokból összeállítani, amelynek a költsége minél kisebb, esetleg minimális. A gráf éleihez tehát nemnegatív költségértékeket rendelünk. Az útszakaszok lehetnek mindkét irányban járhatók, ha például a navigációs probléma az ország térképén két város között merül fel, illetve lehetnek egyirányúak, ha egy városon belül keresünk legrövidebb utat két pont között. Ennek megfelelően a gráf egyaránt lehet irányítás nélküli, illetve irányított.
A gráfon megfogalmazott, minimális költségű útvonal keresése során alapesetben nem támaszkodhatunk más ismeretre, mint az élsúlyok értékére. Nincs olyan háttértudásunk, amely eleve kizárná bármelyik csúcsot az útvonalból. A feladatot ezért az általános esetben úgy fogalmazzuk meg, hogy egy kiinduló csúcsból a gráf minden pontjához keressük az oda vezető minimális költségű utat.
A kitűzött feladat megoldására Dijkstra nevezetes algoritmusát ismertetjük. Ez egy mohó eljárás, amely a startcsúcsból kiindulva, minden lépésben az addigi legkisebb költséggel elérhető csúcsot választja ki, és annak szomszédjaiba új költségeket számol. (Könnyen felismerhetjük majd, hogy a szélességi bejárásnál – egyszerűbb esetben – találkoztunk már ennek a megoldásnak az elvével.)
Az eljárás ismertetésénél újra hasznát vesszük annak, hogy megkülönböztetjük az absztrakt adatszerkezet, illetve az adatok reprezentálásnak a szintjét. Az ADS szinten megadott algoritmus nem csak szemléletes, hanem a megengedhető mértékig nem-determinisztikus, valamint az eltérő reprezentációk közös kiindulópontját képezi. Adatábrázolás szintjén mindkét gráf-reprezentációra, valamint az algoritmusban szereplő elsőbbségi sor két megvalósítására meggondoljuk a műveletigényét.
A bevezetőben körvonalazott problémát pontosabban is megfogalmazzuk, mint gráfon értelmezett feladatot.
Feladat. Adott egy G=(V,E) élsúlyozott, véges gráf és egy 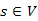 csúcs, a kezdőcsúcs. A gráf élei lehetnek irányítatlanok, és rendelkezhetnek irányítással. Szeretnénk meghatározni minden
csúcs, a kezdőcsúcs. A gráf élei lehetnek irányítatlanok, és rendelkezhetnek irányítással. Szeretnénk meghatározni minden 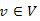 csúcsra az s-ből v-be vezető legkisebb költségű utat, a költségértékével együtt.
csúcsra az s-ből v-be vezető legkisebb költségű utat, a költségértékével együtt.
Elterjedt az a szóhasználat, amely a kezdőcsúcsot startcsúcsnak vagy forrásnak nevezi, a minimális költségű utat pedig optimális útnak, vagy (kissé megtévesztően) legrövidebb útnak mondja, amit mindjárt meg is indokolunk.
Módosítsuk a szélességi bejárásnál bevezetett úthossz fogalmunkat. Legyen G=(V,E) élsúlyozott, irányított vagy irányítás nélküli gráf 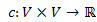 súlyfüggvénnyel. A
súlyfüggvénnyel. A 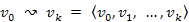 út költsége (összsúlya, hossza) az utat alkotó élek súlyainak az összege, azaz
út költsége (összsúlya, hossza) az utat alkotó élek súlyainak az összege, azaz

Vezessük be a legkisebb költségű (minimális költségű, optimális vagy legrövidebb) út fogalmát. Az u-ból a v-be (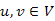 ) vezető minimális költségű út súlya (összköltsége, hossza) legyen
) vezető minimális költségű út súlya (összköltsége, hossza) legyen
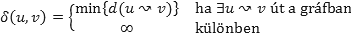
Az u csúcsból a v-be vezető legrövidebb úton a 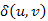 súlyú utak egyikét értjük.
súlyú utak egyikét értjük.
A szélességi keresésnél már találkoztunk hasonló feladattal, az ottani legrövidebb (legkisebb élszámú) utak nyilvántartásával. Most is ugyanúgy járunk el, egy P[1..n] tömbben tartjuk nyilván minden csúcsnak a megelőzőjét, az algoritmus által talált (egyik) legrövidebb úton.
A szélességi fához hasonlóan definiálhatjuk a legrövidebb utak feszítőfáját is. Az 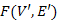 gráf a G = (V,E) gráfban a legrövidebb utak fája, ha V' elemei az s-ből elérhető csúcsok,
gráf a G = (V,E) gráfban a legrövidebb utak fája, ha V' elemei az s-ből elérhető csúcsok, 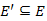 és minden
és minden 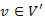 csúcsra pontosan egy egyszerű út vezet s-ből v-be, és ez az út egyike az s-ből v-be vezető legrövidebb G-beli utaknak.
csúcsra pontosan egy egyszerű út vezet s-ből v-be, és ez az út egyike az s-ből v-be vezető legrövidebb G-beli utaknak.
A megoldás elve a következő. Minden lépésben tartsuk nyilván az összes csúcsra, a forrástól az illető csúcsba vezető, eddig talált legkisebb összsúlyú utat. A már megismert módon a d[1..n] tömbben a távolságot, és P[1..n] tömbben a megelőző csúcsot tároljuk.
Azt mondhatjuk, hogy egy 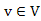 csúcs már KÉSZ, ha ismert a hozzá vezető legrövidebb út. Kezdetben egyetlen csúcs sem KÉSZ, és azt szeretnénk elérni, hogy az eljárás először magát az s kezdőcsúcsot válassza ki, hiszen innen indul a keresés és formálisan nézve az önmagából hozzá vezető legrövidebb út nulla költsége eleve ismert.
csúcs már KÉSZ, ha ismert a hozzá vezető legrövidebb út. Kezdetben egyetlen csúcs sem KÉSZ, és azt szeretnénk elérni, hogy az eljárás először magát az s kezdőcsúcsot válassza ki, hiszen innen indul a keresés és formálisan nézve az önmagából hozzá vezető legrövidebb út nulla költsége eleve ismert.
1.Kezdetben a forrástól vett távolság legyen a kezdőcsúcsra 0, a többi csúcsra  .
.
2.Minden lépésben a nem KÉSZ csúcsok közül tekintsük az egyik legkisebb eddigi költségű v csúcsot. A v-t terjesszük ki, azaz a szomszédjaira számítsuk ki a v-be vezető, és onnan egy kimenő éllel meghosszabbított út költségét. Amennyiben ez jobb (kisebb), mint az illető szomszédba eddig talált legrövidebb út összsúlya, akkor innen kezdve ezt az utat tekintsük az adott szomszédba vezető, eddig talált legrövidebb útnak. Ezt az eljárást szokás közelítésnek is nevezni.
Az algoritmus helyességét több lépésben igazoljuk.
1.Állítás. A 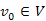 csúcsból a
csúcsból a 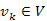 csúcsba vezető, bármely legrövidebb
csúcsba vezető, bármely legrövidebb 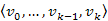 út olyan, hogy a
út olyan, hogy a 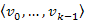 út is egyike a
út is egyike a 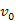 -ból a
-ból a 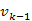 -be vezető legrövidebb utaknak.
-be vezető legrövidebb utaknak.
Bizonyítás. Az úthossz definíciójából tudjuk, hogy 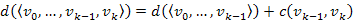 . Indirekt tegyük fel, hogy létezik
. Indirekt tegyük fel, hogy létezik 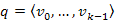 útnál rövidebb p út
útnál rövidebb p út 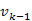 -be. Ekkor ezen az úton eljutva -be az úthossz:
-be. Ekkor ezen az úton eljutva -be az úthossz: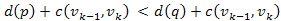 , mivel d(p) < d(q). Tehát találtunk a legrövidebb útnál rövidebb utat, ami ellentmondás.
, mivel d(p) < d(q). Tehát találtunk a legrövidebb útnál rövidebb utat, ami ellentmondás.
2.Az előző állításból következik, elegendő a legrövidebb úton csak a megelőző csúcsot eltárolni. Az állítás könnyen általánosítható "a legrövidebb út részútja is legrövidebb út" állításra.
3.Állítás. 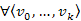 úton, a
úton, a 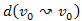 ,
, 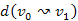 , ...,
, ..., 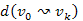 részutak költségei monoton növő sorozatot alkotnak.
részutak költségei monoton növő sorozatot alkotnak.
Bizonyítás. Mivel nincsenek negatív élsúlyok, ezért 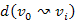 , i=0 ...k nem negatív tagú sorozatnak tekinthető.
, i=0 ...k nem negatív tagú sorozatnak tekinthető.
4.Állítás. Az egyes lépések után, 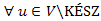 csúcs esetén, ha
csúcs esetén, ha 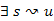 út a gráfban, akkor az u csúcshoz vezető legrövidebb úton
út a gráfban, akkor az u csúcshoz vezető legrövidebb úton 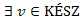 csúcs.
csúcs.
Bizonyítás. Az 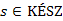 biztosan teljesül.
biztosan teljesül.
5.Állítás. Minden lépésben, 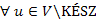 csúcsra teljesül
csúcsra teljesül 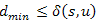 , azaz s-ből u-ba vezető utak távolsága nem csökkenhet a jelenlegi minimum alá.
, azaz s-ből u-ba vezető utak távolsága nem csökkenhet a jelenlegi minimum alá.
Bizonyítás. Az első lépésben triviálisan teljesül az állítás, mivel 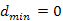 és nincs negatív élsúly. Indirekt tegyük fel, hogy
és nincs negatív élsúly. Indirekt tegyük fel, hogy 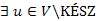 , amelyre az eddig talált legrövidebb p út
, amelyre az eddig talált legrövidebb p út 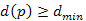 , de a legrövidebb
, de a legrövidebb 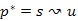 útra
útra 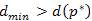 . Tudjuk, hogy van KÉSZ csúcsa a
. Tudjuk, hogy van KÉSZ csúcsa a 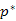 útnak (2. lépéstől kezdve). Legyenek
útnak (2. lépéstől kezdve). Legyenek 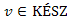 és
és 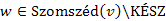 egymást követő csúcsai -nak (biztos létezik w, mivel
egymást követő csúcsai -nak (biztos létezik w, mivel 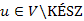 , legfeljebb w = u). Mivel , így már ismert v-be vezető egyik legrövidebb út, ami része az u-ba menő egyik legrövidebb útnak. Legyen u-ba menő egyik legrövidebb útnak w-ig tartó részútja
, legfeljebb w = u). Mivel , így már ismert v-be vezető egyik legrövidebb út, ami része az u-ba menő egyik legrövidebb útnak. Legyen u-ba menő egyik legrövidebb útnak w-ig tartó részútja 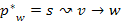 , aminek a hossza már ismert, mivel v-t már KÉSZ-nek választottuk, ezért
, aminek a hossza már ismert, mivel v-t már KÉSZ-nek választottuk, ezért 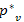 ismert, továbbá v-t kiterjesztettük, így is ismert. Azt is tudjuk, hogy
ismert, továbbá v-t kiterjesztettük, így is ismert. Azt is tudjuk, hogy 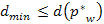 , mivel
, mivel 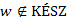 . A monotonitás tulajdonság miatt
. A monotonitás tulajdonság miatt 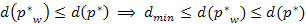 , ami ellentmond az indirekt feltevésnek.
, ami ellentmond az indirekt feltevésnek.
6.Állítás. Az egyes lépésekben az algoritmus által KÉSZ-nek kiválasztott 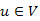 csúcsra valóban ismert az egyik legrövidebb
csúcsra valóban ismert az egyik legrövidebb 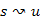 út.
út.
Bizonyítás. Legyen 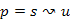 a jelenleg ismert legrövidebb út (ami lehet távolságú is), amelyre tudjuk
a jelenleg ismert legrövidebb út (ami lehet távolságú is), amelyre tudjuk 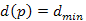 , és indirekt tegyük fel, hogy
, és indirekt tegyük fel, hogy 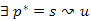 út, amelyre
út, amelyre 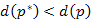 . Tudjuk, hogy
. Tudjuk, hogy 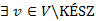 és
és 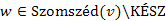 csúcs a úton. A korábbiakban látott módon levezethető, hogy
csúcs a úton. A korábbiakban látott módon levezethető, hogy 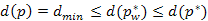 ami ellentmond az indirekt feltevésnek. Tehát rövidebb
ami ellentmond az indirekt feltevésnek. Tehát rövidebb 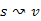 utat a későbbiekben sem találhatunk.
utat a későbbiekben sem találhatunk.
7.Állítás. A fenti algoritmus, negatív élsúlyokat nem tartalmazó G=(V,E) véges gráf esetén, forrás (kezdőcsúcs) és 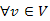 csúcsra, meghatározza s-ből v-be vezető legrövidebb utat és annak hosszát.
csúcsra, meghatározza s-ből v-be vezető legrövidebb utat és annak hosszát.
Bizonyítás. Az algoritmus minden lépésben KÉSZ-nek választ egy csúcsot. Mivel véges sok csúcsa van a gráfnak, az algoritmus véges időn belül terminál, és 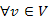 csúcs KÉSZ-en van, azaz ismert a legrövidebb
csúcs KÉSZ-en van, azaz ismert a legrövidebb 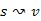 út.
út.
A d[1..n] és P[1..n] tömböket, a korábban ismertetett módon, a távolság és a megelőző csúcs nyilvántartására használjuk. A KÉSZ halmazba rakjuk azokat a csúcsokat, amelyekhez már ismerjük az egyik legrövidebb utat. Ezen kívül, használunk egy minimumválasztó elsőbbségi (prioritásos) sort (minQ), amelyben a csúcsokat tároljuk a már felfedezett, legrövidebb 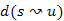 távolsággal, mint kulcs értékkel.
távolsággal, mint kulcs értékkel.
A Dijkstra algoritmusa a 24.1. ábrán látható.
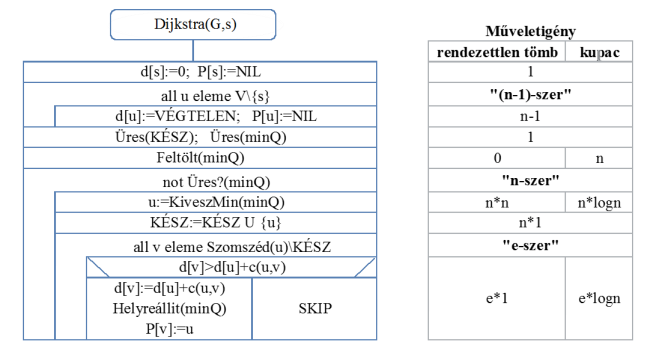 fej24_01_full.png24.1. ábra. A Dijkstra algoritmus és műveletigénye
fej24_01_full.png24.1. ábra. A Dijkstra algoritmus és műveletigényeVizsgáljuk meg a prioritásos sor (minQ) megvalósításának két, természetes módon adódó lehetőségét.
1.A prioritásos sort valósítsuk meg rendezetlen tömbbel, azaz a prioritásos sor legyen maga a d[1..n] tömb. Ekkor a minimum kiválasztására egy feltételes minimum keresést kell alkalmazni, amelynek a műveletigénye 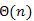 . A Feltölt(minQ) és a Helyreállít(minQ) absztrakt műveletek megvalósítása pedig egy SKIP-pel történik.
. A Feltölt(minQ) és a Helyreállít(minQ) absztrakt műveletek megvalósítása pedig egy SKIP-pel történik.
2.Kupac adatszerkezet használatával is reprezentálhatjuk a prioritásos sort. Ekkor a Feltölt(minQ) eljárás, egy kezdeti kupacot épít, amelynek a műveletigénye lineáris (lásd: 16. fejezet). Azonban most a d[1..n] tömb változása esetén a kupacot is karban kell tartani, mivel a kulcs érték változik. Ezt a Helyreállít(minQ) eljárás teszi meg, amely a csúcsot a gyökér felé "szivárogtatja" fel, ha szükséges (mivel a kulcs értékek csak csökkenhetnek). Ennek a műveletigénye 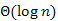 -es.
-es.
Megjegyzés. Nem szükséges kezdeti kupacot építeni, felesleges a kupacba rakni a végtelen távolságú elemeket. Kezdetben csak a kezdőcsúcs legyen a kupacban, majd amikor először elérünk egy csúcsot és a távolsága már nem végtelen, elég akkor berakni a kupacba.
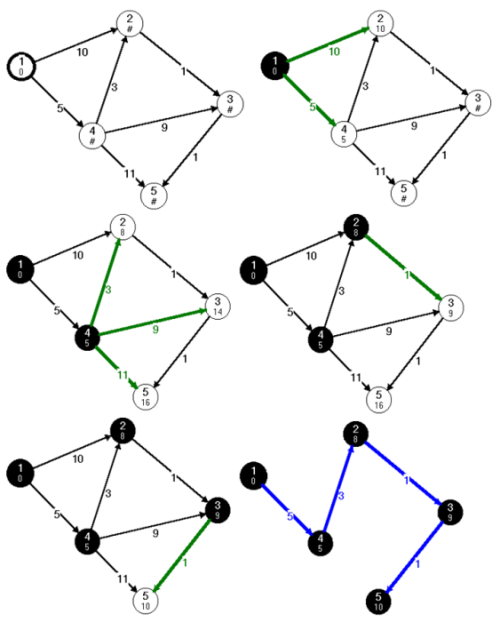
A 24.2. ábrán megfigyelhető Dijkstra algoritmusának működése lépésenként. A KÉSZ halmazhoz való tartozást színezéssel valósítjuk meg. Legyenek a nem KÉSZ csúcsok fehérek, a KÉSZ csúcsok pedig fekete színűek. A csúcsokra a címkén kívül, felírtuk az eddig talált legrövidebb út hosszát is (d tömbbeli értékeket). A végtelen nagy távolságot jelöljük '#' jellel. A forrás legyen az 1-es címkéjű csúcs.
Az inicializáló lépés után a kezdőcsúcs 0, a többi csúcs végtelen súllyal szerepel az elsőbbségi sorban. Az első lépésben kivesszük a prioritásos sorból az 1-es csúcsot (mivel az ő prioritása a legkisebb). Az 1-es csúcshoz már ki van számítva a legrövidebb út, tehát ez a csúcs már elkészült, színezzük feketére. Kiterjesztjük az 1-est, azaz a szomszédjaira kiszámítjuk az 1-esből kimenő éllel meghosszabbított utat. Ha ez javító él, azaz az 1-esen átmenő út rövidebb, mint az adott szomszédba eddig talált legrövidebb út, akkor a szomszédban ezt feljegyezzük (d és P tömbbe). Az ábrán kiemeltük a javító éleket. Megfigyelhető, hogy a 2-es csúcsba már korábban is találtunk 10 hosszú utat 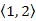 , de a második lépésben, a 4-es csúcs kiterjesztésekor, találunk, a 4-es csúcson átmenő rövidebb 8 hosszú utat. A 2-es csúcs kiterjesztésekor a 3-as csúcsba találtunk egy rövidebb utat. A negyedik lépésben még találunk rövidebb utat az 5-ös csúcsba, majd az utolsó lépésben kivesszük a prioritásos sorból az 5-ös címkéjű csúcsot is. Az utolsó lépésben berajzoltuk a legrövidebb utak fáját alkotó éleket.
, de a második lépésben, a 4-es csúcs kiterjesztésekor, találunk, a 4-es csúcson átmenő rövidebb 8 hosszú utat. A 2-es csúcs kiterjesztésekor a 3-as csúcsba találtunk egy rövidebb utat. A negyedik lépésben még találunk rövidebb utat az 5-ös csúcsba, majd az utolsó lépésben kivesszük a prioritásos sorból az 5-ös címkéjű csúcsot is. Az utolsó lépésben berajzoltuk a legrövidebb utak fáját alkotó éleket.
 fej24_s1_full.png24.2. ábra. A Dijkstra algoritmus lépésenkénti végrehajtása
fej24_s1_full.png24.2. ábra. A Dijkstra algoritmus lépésenkénti végrehajtásaA prioritásos sor fenti két megvalósítása esetén, a következőképpen alakul az algoritmus műveletigénye. A 24.1-es ábrán feltüntettük az egyes műveletek költségét a két ábrázolás estén. A belső ciklust célszerű globálisan kezelni, ekkor mondható, hogy összesen legfeljebb annyiszor fut le, ahány éle van a gráfnak.
1.Rendezetlen tömb esetén:
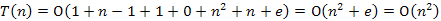
2.Kupac esetén:
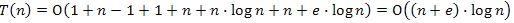
Rendezetlen tömbbel való ábrázolás műveletigénye csak a csúcsok számától függ, míg a kupacos ábrázolás műveletigénye, az élek számának is a függvénye. Sűrű gráfnak nevezzük az olyan gráfokat, amelyre 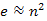 , ritka gráfoknak pedig, amelyre
, ritka gráfoknak pedig, amelyre 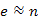 (vagy "kevesebb"). Tehát a kupacos ábrázolás műveletigénye ritka gráf esetén
(vagy "kevesebb"). Tehát a kupacos ábrázolás műveletigénye ritka gráf esetén 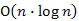 , míg sűrű gráf esetén
, míg sűrű gráf esetén 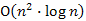 . Az az érdekes helyzet adódott, hogy a gráf sűrűsége befolyásolja milyen ábrázolást érdemes választani. A kupac, csak a ritka gráfok esetén hatékonyabb, míg sűrű gráfok esetén a rendezetlen tömbbel való reprezentáció az olcsóbb.
. Az az érdekes helyzet adódott, hogy a gráf sűrűsége befolyásolja milyen ábrázolást érdemes választani. A kupac, csak a ritka gráfok esetén hatékonyabb, míg sűrű gráfok esetén a rendezetlen tömbbel való reprezentáció az olcsóbb.
Tehát a reprezentáció szintjén sűrű gráf esetén csúcsmátrix és rendezetlen tömb, titka gráf esetén szomszédsági lista és kupac javasolt.
A mohó algoritmus mindig az adott lépésben optimálisnak látszó döntést hozza, vagyis a lokális optimumot választja abban a reményben, hogy ez globális optimumhoz fog majd vezetni. Dijkstra algoritmusa is mohó stratégiát követ, amikor minden lépésben KÉSZ-nek választ egy csúcsot. Mivel a legrövidebb út részútja is legrövidebb út, így a lokális optimumok választásával elérhetjük a globális optimumot.
Most vizsgáljuk meg a szélességi keresés és a Dijkstra algoritmus kapcsolatát. Mindkét algoritmusnál, egy kezdőcsúcsból kiinduló legrövidebb utakat állítunk elő, csak a Dijkstra algoritmusnál az utak hosszának fogalmát általánosítjuk. Legyen minden él súlya egységnyi, ekkor a Dijkstra algoritmus egy szélességi keresést hajt végre. Tehát mondhatjuk, hogy a szélességi keresés speciális esete a Dijkstra algoritmusnak, ahol a prioritásos sor helyett, egy egyszerű sort használunk, amellyel javítunk a műveletigényen. Azt kell belátni, hogy a sor használatával is mindig a legkisebb távolságú csúcsot választjuk KÉSZ-nek, de ez következik a szélességi keresésnél megvizsgált invariáns tulajdonságból.
 |
 |
A tananyag az ELTE - PPKE informatika tananyagfejlesztési projekt (TÁMOP-4.1.2.A/1-11/1-2011-0052) keretében valósult meg.
A tananyag elkészítéséhez az ELTESCORM keretrendszert használtuk.